1. La pregunta que más se le hace a un estadístico es: «¿Qué tamaño de muestra necesito?».
2. El problema que tiene esta pregunta es que, así, sin más, no tiene respuesta. Es una pregunta que engendra preguntas porque el estadístico, sin más información, no puede decir nada, como veremos a continuación.
3. Es conveniente diferenciar dos ámbitos distintos en la determinación del tamaño de muestra: a) Cuando hacemos una predicción. b) Cuando hacemos un contraste de hipótesis. Empezaremos planteando el primer caso y, en concreto, ejemplificado en la predicción de una media poblacional.
4. El radio (r) de un intervalo de confianza de la predicción de la media poblacional, la Desviación estándar (DE) y el tamaño muestral (n) mantienen una relación que puede expresarse en una ecuación muy importante en Estadística:
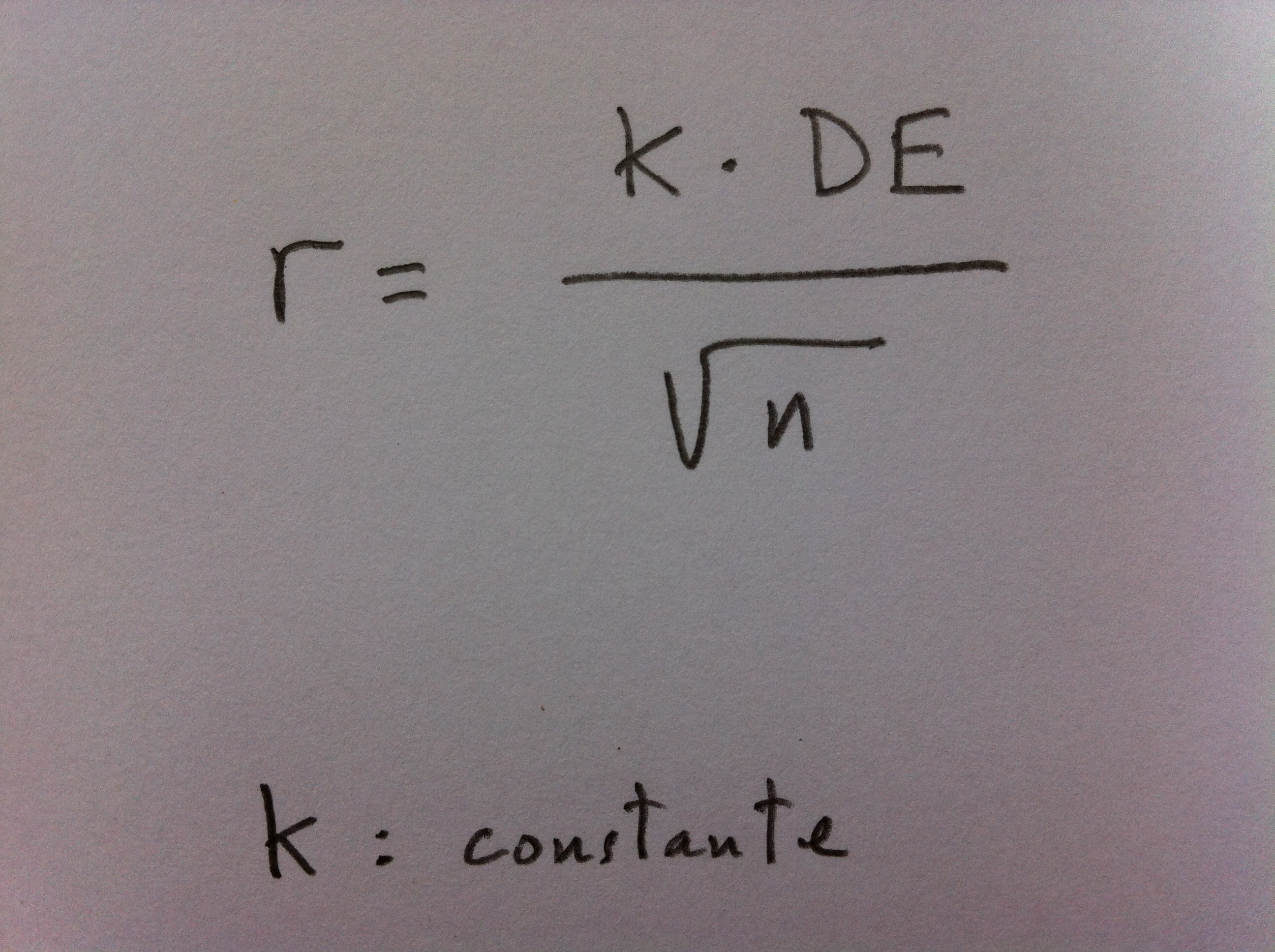
5. Recordemos que un intervalos de confianza de la media como, por ejemplo: (5, 15), tiene como radio 5 y como diámetro tendría 10. Y recordemos, también, que estos intervalos tienen un porcentaje de confianza. Recordemos, también, que esta expresión la podemos deducir de todo lo visto en el Tema 3: Intervalos de confianza.
6. Esta constante k dependerá de ese porcentaje de confianza con el que queramos expresar el pronóstico. En el caso de que estemos trabajando con la media poblacional y en caso de seguir, nuestra variable, la distribución normal, o, si no es así, que el tamaño muestral sea grande (superior a 30) este valor de k, si el nivel de confianza es del 95%, es aproximadamente 2.
7. Por lo tanto, la ecuación quedaría así:
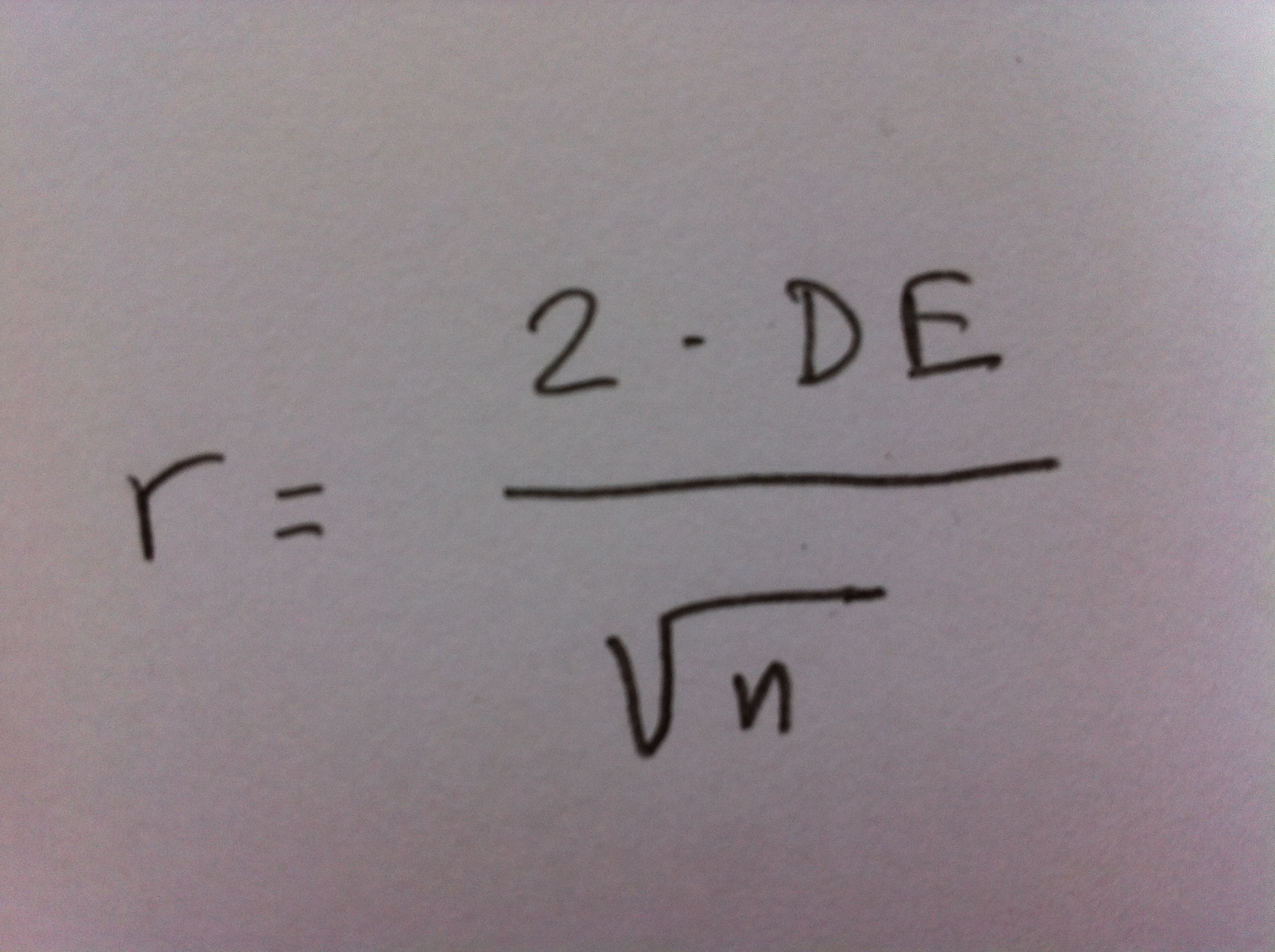
8. Vamos a reflexionar algunas cosas importantes que se desprenden de esta importantísima igualdad.
9. Esta ecuación no aparece por arte de magia, surge de la fundamental noción de Error estándar (EE), cuya expresión recordemos que, para el pronóstico de la media poblacional, es EE=DE/raiz(n).
10. De hecho, ya lo hemos dicho en diferentes ocasiones, que en cualquier estimación, en cualquier pronóstico, está implicado el Error estándar. El EE es una DE, pero es la DE de una predicción. Esto es lo que lo caracteriza.
11. Pero, además, hemos visto también que la noción de EE era fundamental para la construcción del intervalo de confianza del 95%.
12. Y en la ecuación r=2•DE/raiz(n) la parte derecha de la igualdad es esa expresión de dos veces el error estándar.
13. Otra forma de expresar esa ecuación, despejando la n, es:
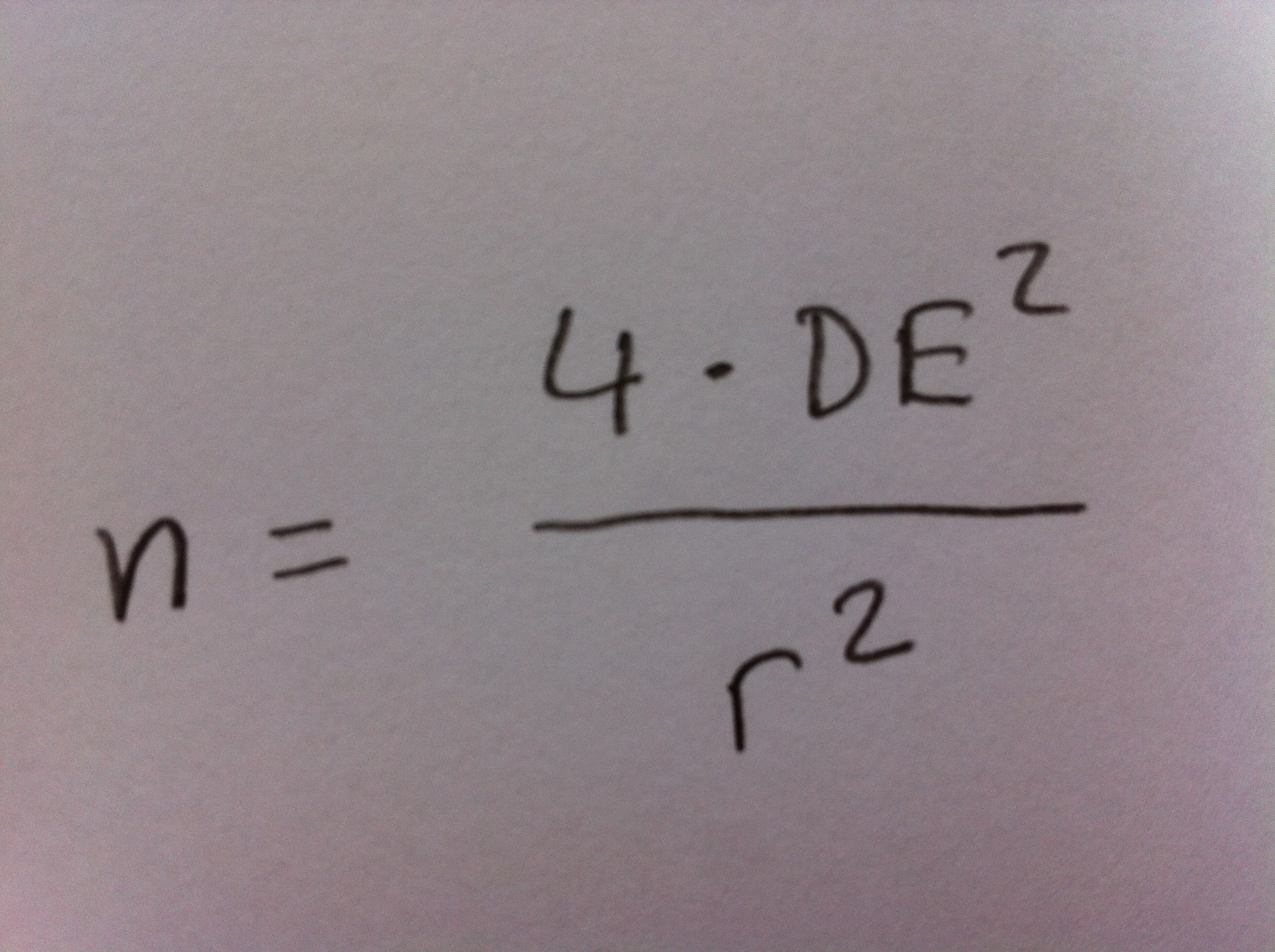
donde ya la tenemos en la forma deseada, porque lo que queremos es determinar el tamaño de muestra, la n, en un estudio concreto.
14. Una vez tenemos la ecuación podemos hacer afirmaciones a partir de ella. En una ecuación la posición relativa de los conceptos es muy importante. Veamos: Si hay mucha dispersión necesitamos más n. Si hay poca dispersión no necesitaremos tanto tamaño de muestra. La relación entre n y la DE es directa. A más DE más n. A menos DE menos n.
15. Si necesitamos una precisión grande en nuestras predicciones; o sea, un radio r pequeño, entonces deberemos tener una muestra grande. Si no necesitamos mucha precisión; o sea, si no precisamos un radio r muy pequeño, la muestra podrá ser menor. Por lo tanto, el tamaño de muestra está relacionado de forma inversa con ese radio del intervalo.
16. O sea, a la hora de elegir un tamaño de muestra debemos saber qué precisión necesitamos y qué dispersión podemos prever que tendremos en la futura muestra. Necesitamos saber, pues, cómo será la muestra que aún no tenemos.
17. Esta paradoja es importante: para elegir un tamaño de muestra ideal necesitamos saber cómo será la dispersión de esa futura muestra.
18. El conocimiento de lo que todavía no conocemos lo debemos suplir por información de otros estudios previos o por una muestra piloto, una pequeña muestra previa, una premuestra, que nos permita hacer una previsión de la dispersión que tenemos en el estudio.
19. Respecto a la precisión requerida en el estudio, expresada ésta por el radio del intervalo (r), no siempre uno sabe lo que le interesa o lo que necesita. En este caso lo que uno quiere es estar lo más cerca del valor que estima. Pero es necesario especificar, de antemano, esa precisión porque de ello depende el tamaño de muestra que hemos de tomar. Porque está en la ecuación.
20. Un ejemplo: Estamos estudiando la media de altura de una población adulta y queremos construir un intervalo de confianza del 95% de la media poblacional cuyo radio no sea mayor que 1; o sea, queremos construir un intervalo de confianza con el valor de la media muestral más menos 1.
21. Observemos que a partir de la ecuación n=4•DE2/r2 sabemos r que vale 1, pero nos falta saber DE. Si sabemos, por otros estudios, que la DE en estas poblaciones es un valor cercano a 10 ya lo tenemos todo para determinar el tamaño de muestra que necesitamos. Entonces el tamaño de muestra ideal para trabajar es: n=4*100/1=400. Con este tamaño de muestra y con esta dispersión podremos construir un intervalo de confianza del 95% de la media poblacional a partir de la media muestral que calculemos a la muestra con un radio de 1.
22. Observemos ahora lo mismo pero visto desde el otro lado: Tomamos una muestra de tamaño 400 y calculamos la media que es, por ejemplo, 170 y la DE que resulta ser, finalmente 10, como ya habíamos predicho por estudios previos. Entonces, al calcular el intervalo de confianza de la media poblacional lo haríamos sumando y restando dos veces el Error estándar. Y el Error estándar, en esta muestra, sería 10/raíz(400)=0.5. El intervalo de confianza sería, entonces, 170±1, que es del nivel de precisión que queríamos.
23. Si la variable es dicotómica (una variable como hombre-mujer o tiene o no diabetes) la fórmula es la misma pero ahora la DE es raíz cuadrada de p(1-p), que es la Desviación estándar de una variable dicotómica. O sea, debemos saber cuál debe ser, aproximadamente, el valor de p que acabaremos estimando para ponerlo en la ecuación. Ante la duda se elige como p el valor de 0.5 que nos daría el máximo valor posible de tamaño muestral. Supongamos que queremos estimar la prevalencia de la diabetes en un país y queremos determinar el tamaño de muestra. Sabemos por otros estudios que debe estar en torno al 10% (0.1 en tanto por 1). Queremos tener un radio del intervalo del 1%. Entonces la fórmula sería: n=4*0,1*0,9/0,0001=3600. El 0,0001 es por el 0,01 al cuadrado. La fórmula general en una variable dicotómica es, pues:
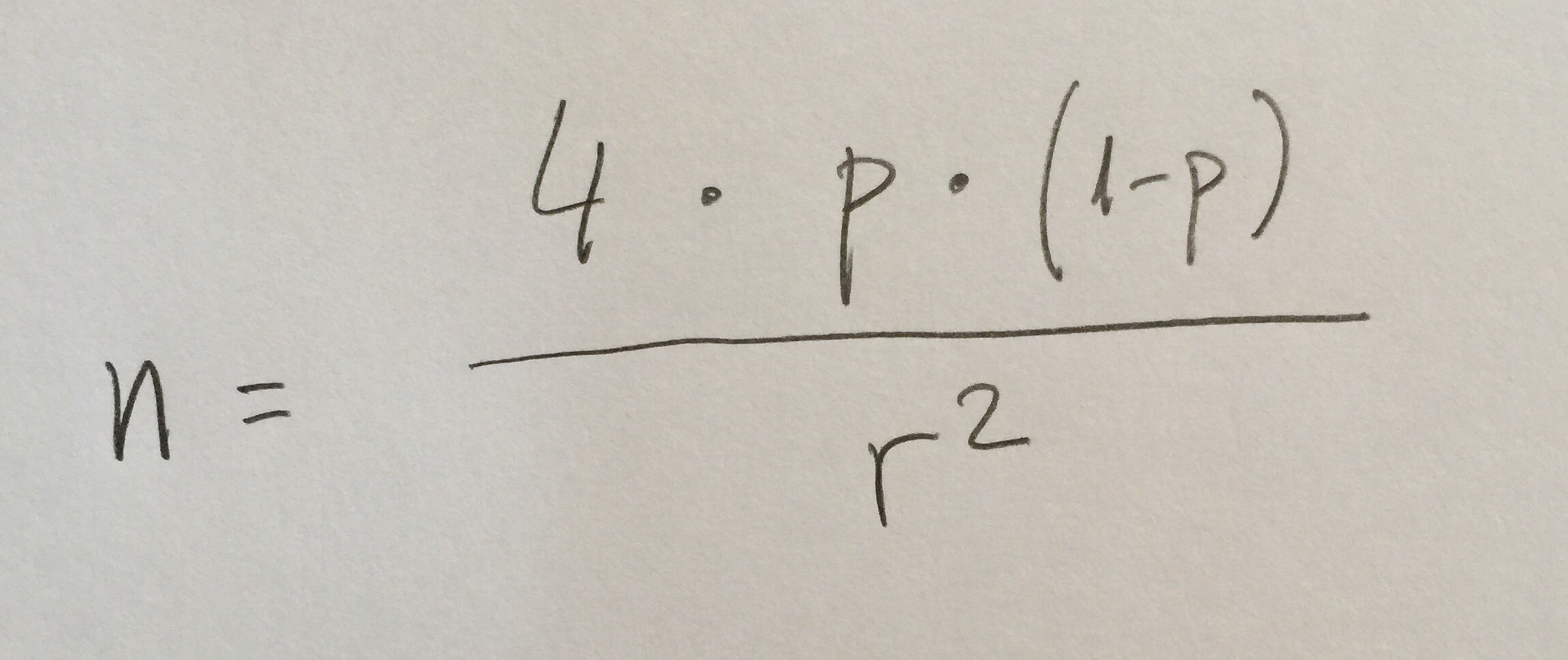
24. Con esto hemos visto que el tamaño de muestra n en un caso de estimación de un valor poblacional, en un caso de un pronóstico poblacional, es una función de la DE y de la precisión requerida, expresada como el radio del intervalo de confianza. Sin estos dos valores no es posible determinar el tamaño de muestra requerido; o sea, expresado en forma funcional, podemos decir que n es función de DE y de r:

25. Sorprende mucho a todo no estadístico que consulta por el tamaño de muestra que necesita (lo repito porque es muy importante que quede muy claro) que precise de la DE antes de coger la muestra, porque es precisamente la muestra la que le acabará dando esa DE. Es aparentemente un círculo vicioso, pero es así. No hace falta tener un valor exacto pero sí aproximado de cuál será la DE con la que se encontrará. Esto puede llegar a saberlo por estudios previos equivalentes hechos por otros o mediante una muestra piloto, o premuestra.
26. Cuando el problema es determinar el tamaño de muestra en un contraste de hipótesis la situación es otra (Recordemos que en el punto 3 hemos visto que la determinación del tamaño de muestra es conveniente verla en dos ámbitos por separado). Entran en juego, ahora, muchos más elementos. En el caso, por ejemplo, de un contraste de la diferencia de medias tendríamos ahora una función de cuatro variables como la siguiente:
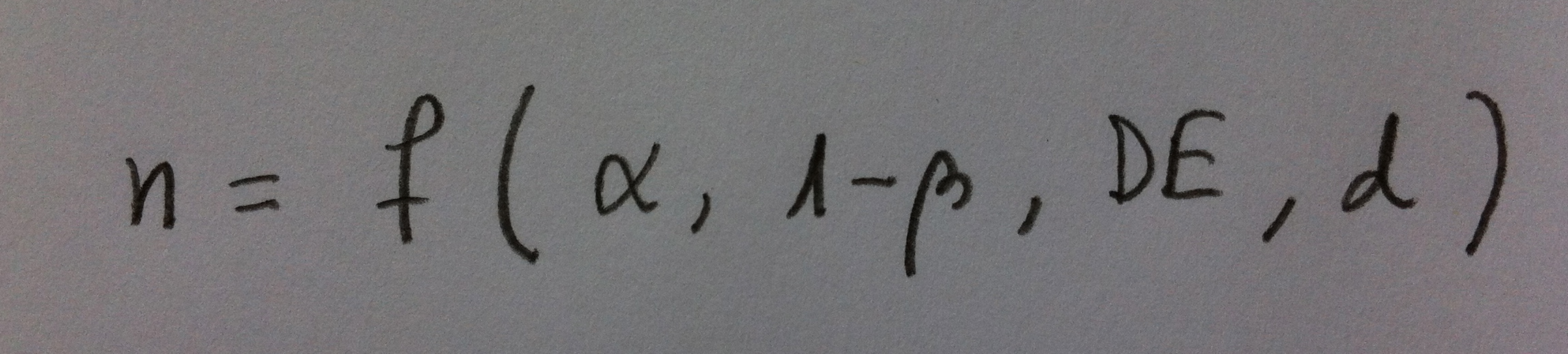
donde alfa es el nivel de significación, 1-beta es la potencia, DE es, como antes, la Desviación estándar y d es la diferencia mínima que interesa detectar.
27. Una función, pues, que depende de cuatro factores, de cuatro valores. Necesitamos más cosas, pues, que antes. Veámoslas una a una: La primera, la alfa, es la menos problemática, es el nivel de significación, es el error de tipo I (Ver el artículo La noción de potencia estadística), solemos fijarla siempre en el valor 0.05.
28. La 1-beta es la potencia estadística (Ver, de nuevo, también, el artículo La noción de potencia estadística). Interesa que sea un valor alto. La beta es, como se puede ver también en ese artículo citado, el denominado error de tipo II, un error que no está fijado de antemano, como sí sucede con el error de tipo I, y que, por lo tanto, conviene conocerlo, puesto que para que el procedimiento de decisión sea bueno deben ser pequeños los dos tipos de error que se pueden cometer. La potencia suele aceptarse que a partir de 0.8 es ya una potencia considerable. Lo ideal, no obstante, sería tenerla de 0.95.
29. Con la DE pasa lo de antes, necesitamos buscar información de estudios similares o tomar una premuestra para saber aproximadamente cuál es su valor.
30. La d suele ser compleja. Al estadístico es lo que le cuesta más conseguir del profesional que necesita de la Estadística. Es, en el caso de tratarse de una comparación de medias, la diferencia mínima que interesa detectar, la diferencia mínima relevante desde el punto de vista médico, económico, lingüístico, etc. (Ver el Tema 9: Significación formal versus Significación material). Podríamos decir que esa d es el valor mínimo por el que tendría valor haber hecho la propia comparación. Un ejemplo, si se trabaja con pacientes hipertensos con media 160 y se ensaya un antihipertensivo se puede fijar una diferencia mínima a detectar de 20 (que baja a 140 la presión, como mínimo), puesto que si es menos de eso no será un buen antihipertensivo.
31. Existen fórmulas para casos específicos, como sucede con la siguiente fórmula para el Test de la t de Student de una muestra:
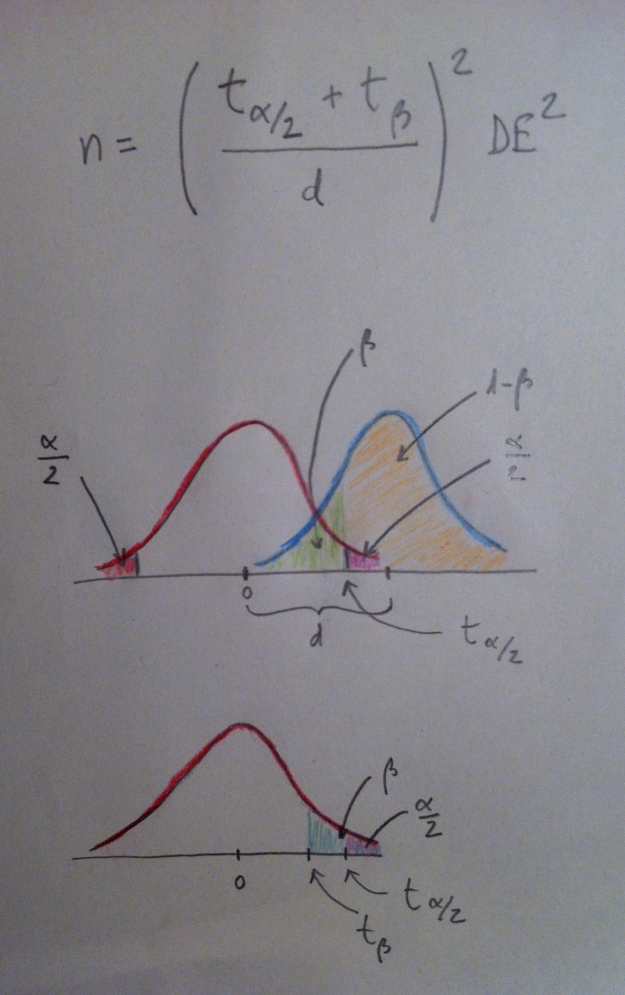
32. Observemos que esta fórmula es interesante para entender todos los conceptos de los que estamos hablando en este tema. Hay en el numerador del cociente interior al paréntesis dos constantes: una que depende de la alfa y otra que depende de la beta. Dependen, pues, ambas constantes, del error que estemos dispuestos a cometer en el proceso de decisión. Cuanto menor sea alfa y beta más grandes serán esas constantes y, por lo tanto, mayor será el tamaño de muestra. Además, como puede verse perfectamente en esta fórmula, en un contraste de hipótesis la determinación del tamaño de muestra es una función de cuatro variables.
33. Existen aplicaciones diferentes muy bien diseñadas para poder elegir el tamaño muestral necesario para un estudio determinado. Pero es fundamental entender todo lo comentado en este Tema para poder usar esas aplicaciones y saber interpretar lo que obtenemos con ellas. Y es básico, además, porque en esta aplicaciones lo primero que te piden es elegir qué tipo de estudio (si comparación de proporciones, de medias, de Odds ratio, etc) y después qué DE tienes, la diferencia mínima a detectar, la potencia que quieres tener, etc.
34. Un enlace excelente para practica todo esto es el siguiente:
http://www.imim.es/ofertadeserveis/software-public/granmo/
35. Unos comentarios para el uso de este enlace. Cuando se comparan dos poblaciones se pide la relación entre los tamaños de muestra. Si es que conviene o es inevitable tener más muestra en una u otra población. Si no es así se añade un 1, que simboliza que puede ser el mismo tamaño muestra. También pide una previsión de los valores que pueden perderse al ir analizando. Esto está pensando para casos donde sea previsible perder un porcentaje de muestra más o menos previsible. Si no se prevé pérdida se pone un 0 en esta opción. Por otro lado el manejo es bastante sencillo. La alfa suele elegirse 0.05, la beta 0.2 ó menos (por lo tanto, potencia 0.8 ó más), la DE la que podamos saber o prever y la diferencia a detectar la mínima que uno está dispuesto a aceptar como relevante antes de empezar el trabajo.
36. Y ahora un breve comentario final a las situaciones de muestras de poblaciones finitas. Nos referimos a situaciones donde la población es pequeña y puede modificar el tamaño de muestra. Hasta ahora estábamos bajo el supuesto de poblaciones lo suficientemente grandes como para considerarlas infinitas.
37. Veamos una fórmula usual que nos ayudará a aclarar las cosas:
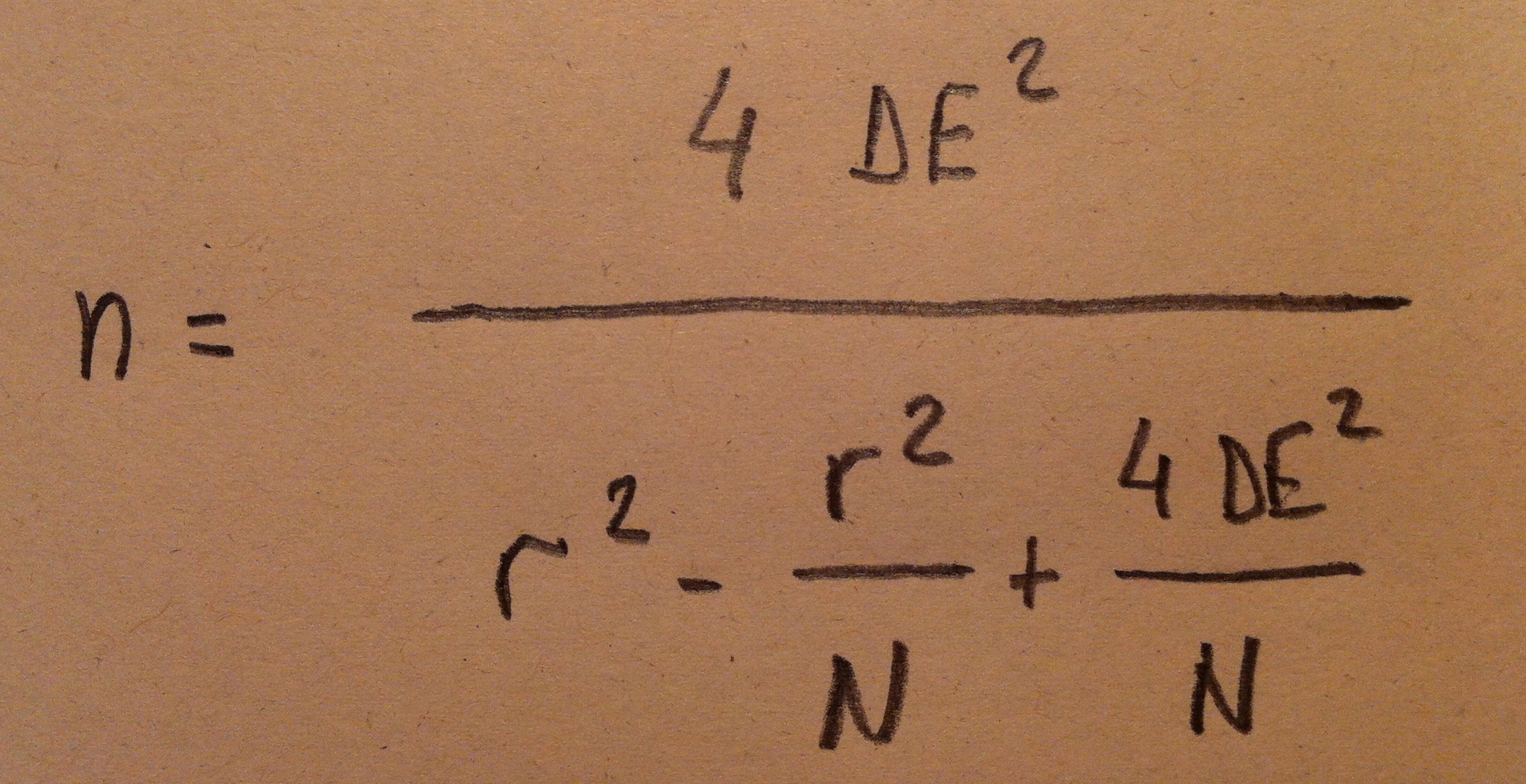
38. Como puede verse es una modificación de una que hemos visto al iniciar este tema. La N es el tamaño de la población. Evidentemente si este valor es muy grande los dos cocientes donde participa se hacen tan pequeños que son insignificantes. Si, por el contrario, esta N es pequeña estos cocientes pueden modificar la n necesaria para tener un determinado tipo de precisión y deberemos tenerla en cuenta.
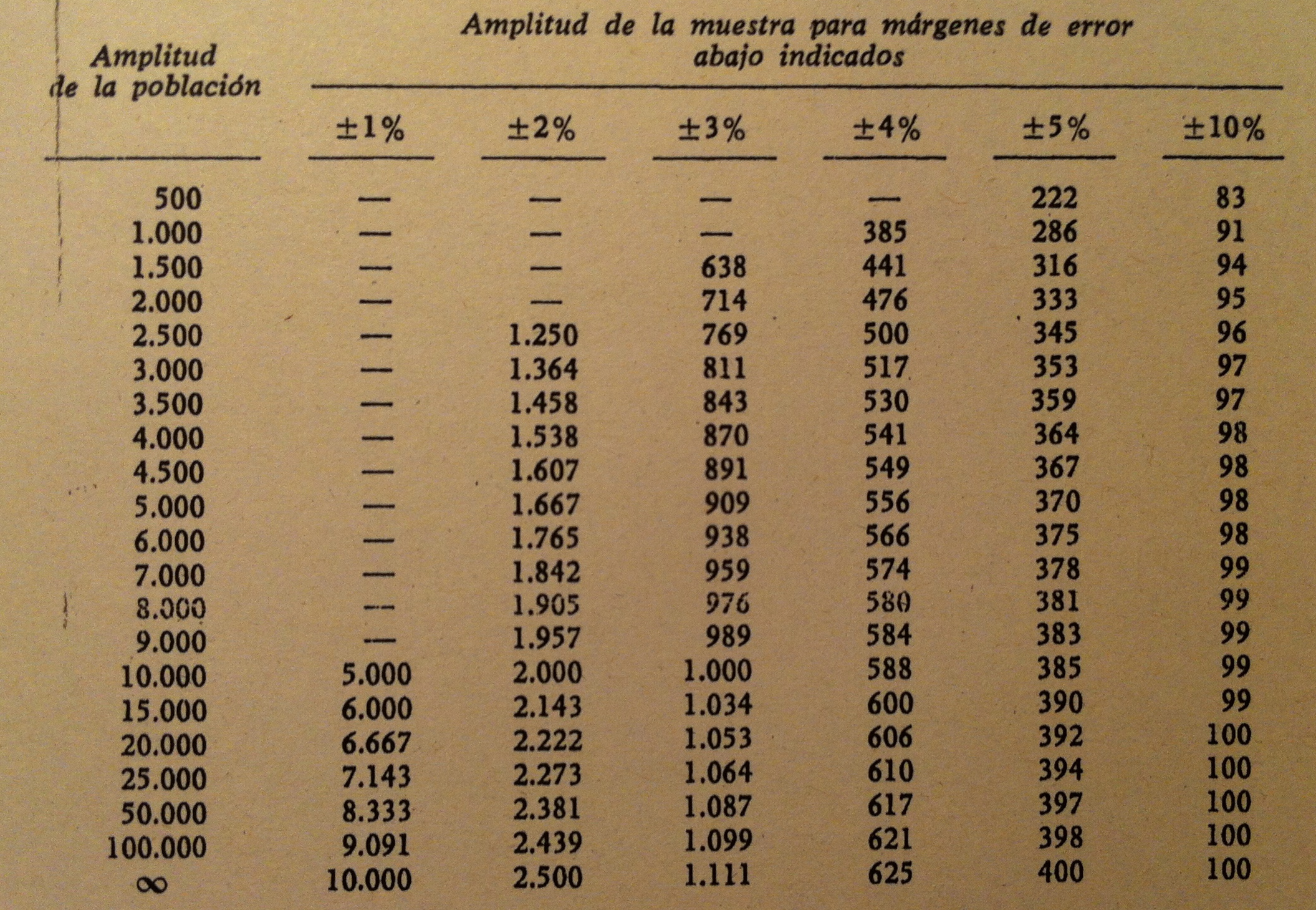
39. A continuación muestro una tabla donde se expresan los cálculos de estas n en condiciones diferentes (en función del radio r y del tamaño poblacional):

agree, it’s really nice.. lista de emails lista de emails lista de emails lista de emails lista de emails
Pingback: Herramientas estadísticas en Medicina (Una hoja de ruta) | LA ESTADÍSTICA: UNA ORQUESTA HECHA INSTRUMENTO
Apreciado Jaume, felicitarte por el gran trabajo hecho es un blog excelente. Además, muchos blogs nacen y mueren al poco tiempo, este continua en plena vitalidad, creciendo día a día; por tanto doble felicitación.
Me gustaría nos especificaras la DE que se debe utilizar en las diferentes situaciones que te paso a comenta en relación a la calculador que referencias en este tema, teniendo presente que hemos hecho una prueba piloto y tenemos valores de los distintos grupos implicados.
1- En el caso de dos medias independientes, la DE estándar común que solicita la calculadora, ¿a qué DE se refiere y cómo se calcula?
2- En el caso de medias apareadas (repetidas en un grupo), la DE de las diferencias, ¿a qué DE se refiere y cómo se calcula?
3- En el caso de un análisis de la varianza, la DE estándar común que solicita la calculadora, ¿a qué DE se refiere y cómo se calcula?
Supongamos que no tenemos una prueba pilota previa:
1- En el caso de la observada respecto a una referencia, la DE estándar común que solicita la calculadora, ¿a qué DE se refiere y cómo se calcula? Si el contraste es de dos medias y tenemos referencias bibliográficas de dos grupos que se parecen a los del estudio y además conocemos el número de sujetos de los estudios (y por tanto podemos calcular la razón), ¿qué formulación utilizaremos?, ¿esta o la de dos medias independientes?
Muchas gracias.
La DE se puede conseguir por estudios previos o con muestras piloto. En datos apareados la DE es de la variable diferencia. En ANOVA la DE es la de cada grupo. Si son algo diferentes coge la más grande.
Apreciado Jaume,
La calculadora Gramno que referencias permite el cálculo de la potencia de contraste de un estudio ya realizado tomando de referencia la DE y la media de dos grupos de estudio.
Dos preguntas al respecto:
1-Como hacer el cálculo si hay más de dos grupos.
2- En caso de grupos con distribución no gaussiana, y que por tanto la media y la desviación estándar no son lo representativo, el cálculo sería igualmente con la media y la desviación estándar.
Gràcias.
So no hay normalidad es conveniente transformar los datos para que haya ajuste.
Pingback: ¿Qué es Informática Médica? – informatica médica y bioestadistica